| 1. Definition eines verteilten
Systems
Es gibt verschiedene Definitionen
für ein verteiltes System. Folgende Definition ist nicht
die schlechteste.
Man stelle sich ein Netzwerk, d.h.
mehrer miteinander verbundene Rechner, vor. Die Rechner sind
als Knoten dargestellt.
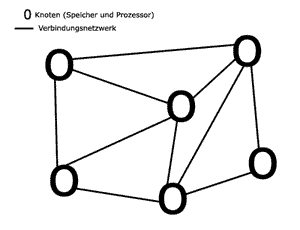
Forderung 1: Knoten sind durch ein
Verbindungsnetzwerk miteinander verbunden.
Forderung 2: Jeder Knoten arbeitet
unabhängig voneinander.
Bei Ausfall eines Knoten, können andere ungehindert weiterarbeiten.
Forderung 3: Jeder Knoten hat mindestens
eine CPU und Speicher.
Damit kann jeder Knoten alleine arbeiten.
Forderung 4: Die Knoten haben keinen
gemeinsamen Speicher.
Diese Forderung ist nötig, da sonst die Knoten nicht
unabhängig wären.
Forderung 5: kein "single point
of failure"
Zentralisierte Einheiten, können beim Ausfall das komplette
Netz lahm legen.
Forderung 6: Verteilungstransparenz
2. Verteilungstransparenz
Unter Verteilungstransparenz sind folgende Transparenzstufen
zusammengefasst:
Zugriffstransparenz
Auf lokale oder entfernte Objekte wird auf gleicher Weise
zugegriffen.
Lokationstransparenz
Auf Objekte wird zugegriffen, ohne Wissen über deren
Lokation.
Replikationstransparenz
Zugriff auf Objekte ohne Wissen über eventuell existierende
Replikate.
Fragmentierungstransparenz
Auf Objekte wird ohne Wissen über eventuell vorliegende
Fragmentierung zugegriffen.
3. Was spricht für ein verteiltes System?
Preis-Leistung
Es ist wesentlich preiswerter mehrere Rechner mit der Gesamtleistung
L zu kaufen als einen einzelnen Großrechner mit der
gleichen Leistung L.
Erweiterbarkeit
Ein verteiltes System kann leicht erweitert werden. Falls
z.B. eine höhere Speicherkapazität gewünscht
wird, so genügt es einen Datei-Server hinzuzufügen.
Falls eine Erhöhung der Rechenkapazität gewünscht
wird, so kann man Prozessoren (Rechner) hinzufügen.
Verfügbarkeit
Ein verteiltes System hat redundante Funktionen und Daten.
Damit kann das System auch bei Ausfall von Komponenten noch
verfügbar sein.
Skalierbarkeit
Durch Vermeidung von zentralisierte Komponenten (single-point-of-failure)
und der Auswahl von geeigneten Algorithmen wird hohe Skalierbarkeit
erreicht.
Zuverlässigkeit
Durch Redundanz und geeignete Recovery-Algorithmen kann ein
hohes Maß an Zuverlässigkeit erreicht werden.
4. Was spricht gegen ein verteiltes System?
Falls die Vorteile eines verteilten System betrachtet werden,
so kann man auch einen großen Nachteil von verteilten
Systemen erkennen, nämlich seine Komplexität.
Vorher unabhängig betriebene
Komponenten (Datenbanksysteme, Internet, Dateisysteme, usw.)
müssen in einem verteilten System zusammenarbeiten. Außerdem
können Fehler sich im Netzwerk fortpflanzen. So kann
der Fehler einer Komponente zum Zusammenbruch des gesamten
Systems führen. Durch die Systemgröße bedingte
Auswirkungen können zum Versagen des verteilten Systems
führen. Grund können Komponenten oder Algorithmen
sein, die schlecht Skalierbar sind und zum Flaschenhals werden.
Bei Ausfall eines Knoten, müssen fehlertolerante Systeme
damit umgehen können. Das sind einige Gründe, warum
ein verteiltes System komplexer ist als ein zentralisiertes
System.
|